Fraud detection with Kinesis Data Analytics
Introduction
In this post, we will deep dive into real time data processing using Kinesis Data Analytics and Kinesis Data Stream. We will start with defining what the real time data processing is, how it differes from batch processing. Next, we will briefly explore Kinesis Data Stream as well as Kinesis Data Analytics, move to Apache Flink basics to end up with building a Fraud detection application on AWS.
Real time data processing
Real time data processing is a method of processing events almost immediately after they were generated, without a need of any waiting or pause. Unlike to batch processing, where the raw data needs to be stored first and processed later on, it requires a data to flow continiously. The adventage is that it gives a data insights immediately letting you act and take actions accordingly. On the other hand, depends on your data stream size, a hardware to process events needs to be powerfull enough to achive best peformance, which may have singnificant impact on the final cost of the solution. Real time data processing brings a few more challenges, like managing events order, fault tolerance and much more.
In real time data processing architecture has the following main components:
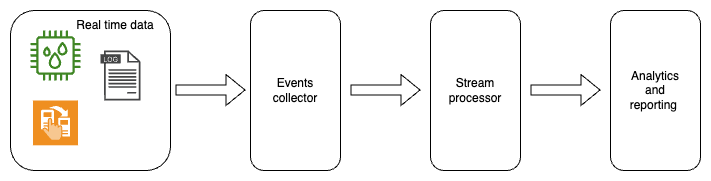
- data source - a process/application/device/etc that produces events
- events collector - a system that stores events in a way that can be retrieved by a stream processor, providing resilience, fault tolerance and scalability (Kinesis Data Stream, Apache Kafka, etc)
- stream processor - an applciation capable to process large amount of events in real time (Kinesis Data Analytics, Apache Spark, Apache Flink, Apache Storm)
- Analytics and reporting - a system triggered by events/insights produced by a stream processor
Kinesis Data Stream
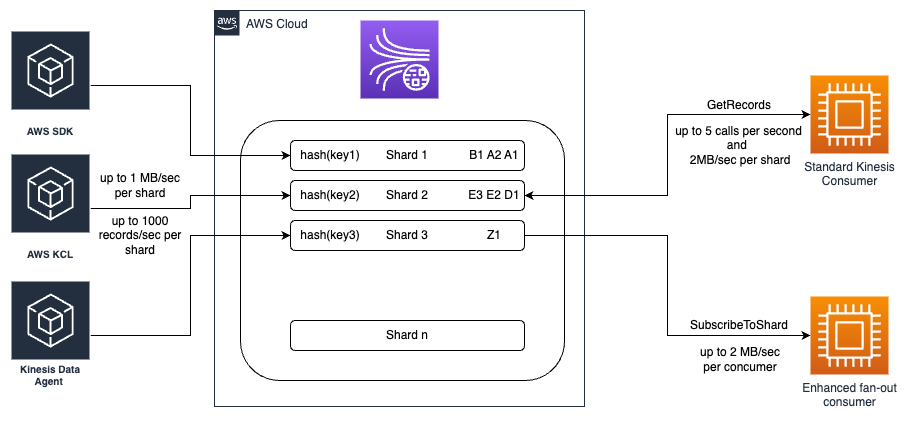
Kinesis Data Stream is a serverless streaming service capable of capturing, processing and storing data stream at any scale. It is built with a set of shards. A shard is a sequence of records composed of unique identifier, partition key and content. Record's partition key is used to organize them in shards. Records with same partition key wil be streamed by the same shard. A shard has defined read and write capacity. In regards to read capacity there are two modes available:
- standard - pull mode with 2 MB/s and 5 GetRecords call per shard for all connected clients
- enhanced fan-out - push mode with 2 MB/s for every connected client
They have different pricing model and should be selected based on your read requirements.
A record in a shard is immutable and cannot be deleted, however it will be removed from a stream after defined retentation period, which can be any value between 24 and 8760 hours (365 days).
A client built on top of AWS SDK (low level API), AWS KPL (Kinesis Producer Library - high level API) or kinesis data agent can write to Kinesis Data Stream. Kinesis agent is a java application that runs as a service, which can monitor set of files and using pre-defined rules send new content to streams. The agent can handle checkpointing, failover recovery or files rotation. It has embedded number of parsers and formatters that can transform your data/log stream into convenient format for the data consumption, e.g. CSV to JSON, LOG to JSON for popular log formats (COMMONAPACHELOG, APACHEERRORLOG, SYSLOG, etc.),
Kinesis Data Analytics
Kinesis Data Analytics provides an easy way to analyze streaming data, gain insights and respond to them in real time. It provides high level abstraction to reduce complexity of building, managing, operting and integrating streaming application with other AWS services. Applications can be built with standard SQL language or as complex Java/Scala programs executed in Apache Flink environment.
Kinesis Data Analytics takes care about all what is needed to run and handle your data stream in real time, including monitoring or scaling to handle high volume of data stream.
Apache Flink
Apache Flink is a framework and distributed processing engine for stateful computations data, both bounded (with defined start and end) and unbounded (with defined started, but not defined end). It provides high level abstraction to operate on large data sets (batches and streams) in a cluster mode with minimum latency leveraging in memory performance. Apache Flink provides very efficient failover recovery mechanism (based on consistent checkpointing) as well as set of tools for monitoring and logging operations. With the available connectors and sinks it supports different deliver modes, including end to end exactly once.
Flink provides three types of API:
- High level analytics API bases on SQL / Table API
The example below shows how to use SQL API to count financial transactions done by a customer within 5 minute tumbling window.
SELECT customerId, COUNT(*)
FROM transactions
GROUP BY TUMBLE(transactionTime, INTERVAL '5' MINUTE), customerId
- Stream and Batch processing API operating on windows
The example below show how to achieve the same with DataStream API.
DataStream<Transaction> transactions = ...
DataStream<Tuple2<String, Long>> result = transactions
// map transaction to a tuple of 2, where first element is a cutomerId and second is a counter
.map(
// define function by implementing the MapFunction interface.
new MapFunction<Transaction, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Transaction transaction) {
return Tuple2.of(transaction.customerId, 1L);
}
})
// key by field 0 - customerId
.keyBy(0)
// define 5 minutes window
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
// sum elements by field 1
.sum(1);
- Low level Statefull events driven functions
And the same functionality with low level api (process function). Details will be discussed in scope of building fraud detector applications.
public class TransactionCounter extends KeyedProcessFunction<String, Transaction, Long> {
private transient ValueState<Long> counterState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Long> counterDescriptor = new ValueStateDescriptor<>(
"counter-state",
Types.LONG);
counterState = getRuntimeContext().getState(counterDescriptor);
}
@Override
public void processElement(
Transaction transaction,
KeyedProcessFunction<String, Transaction, Long>.Context context,
Collector<Long> collector
) throws Exception {
Long previousCounter = counterState.value();
if (previousCounter == null) {
counterState.update(1);
long timer = context.timerService().currentProcessingTime() + (5 * 1000 * 60);
context.timerService().registerProcessingTimeTimer(timer);
} else {
counterState.update(previousCounter++);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Long> out) {
out.collect(counterState.value())
counterState.clear();
}
}
When referring to the time in stream processing, Flink support different notions of time:
- processing time - referes to the system time of the machine that executes the program
- event time - refers to the time, when the event occured
Depends on the time characteristic the processing result might be different (processing time gives the best performance, however results might not be deterministic as mainly depend on the performance of a machine doing calculations). When it comes to event time notion, it is required for a program to defines watermarks generation strategy.
Fraud detection application
Now, we will build a "Fraud detection" application and run it as Kinesis Data Analytics service.
These are the three requirements we need to address to detect a fraud:
- a transaction done with a card that was locked - if we detect a card transaction done by a locked card, we will report an alert for the transaction
- excessive number of transactions within a short period of time - for instance 10 transactions for the same card/customer within e.g. 30s it is something that could not have been done by a real person and such an activity should be reported
- a small transaction followed by a large one - e.g. 1$ and 900$ transactions withing a minute may help us to detect a scammer
Both data streams, transactions and locked cards, would be provided to the application by separate kinesis streams. When it comes to generating alerts/reporting frauds we will also use kinesis data stream. That could be later on integrated with SNS by a lambda in between.
Each of the requirement will be implement using different stream processing pattern.
When it comes to the transactions, we will build a simulator that would generate random data for us. The data will be pushed to streams using kinesis data agent.
Very high level architecture diagram for the solution:
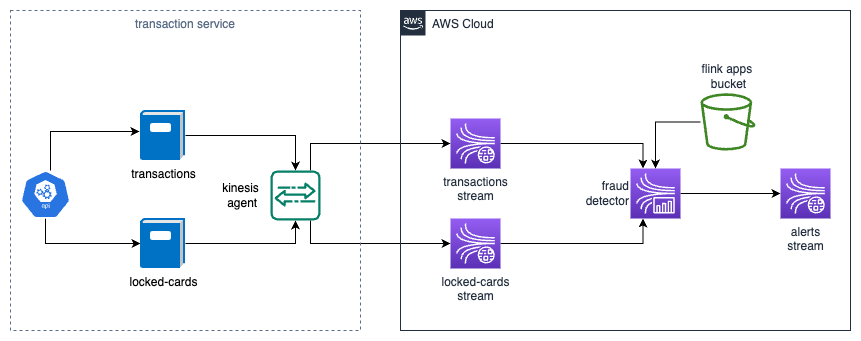
Transactions generator
To generate transactions we will implement a simple NodeJS program that creates random transactions as well as locked cards and writes them to separate files using winston logger. Kinesis data agent will watch the files and push all new records to separate kinesis data streams.
Create an empty TypeScript NodeJS project (you can use guide from the previous post) and add winston logger as dependency.
Next step is to define loggers to write transactions and locked cards information. Create a logger.ts file in src directory add first logger:
// ./src/loggers.ts
export const lockedCardLogger = createLogger({
transports: [
new transports.File({
filename: 'logs/locked-cards.log',
})
],
format: format.printf(({ message }) => {
return `${message}`;
}),
});
The first logger will simply put a message as provided in argument to locked-cards.log.
We need to add another one, very similar to lockedCardLogger. The difference is that it will additionally log the information on the console as well as a transaction will be preceded by a timestamp generated upon log entry creation.
// ./src/loggers.ts
export const transactionLogger = createLogger({
transports: [
new transports.File({
filename: 'logs/transactions.log',
}),
new transports.Console(),
],
format: format.printf(({ message }) => {
return `${new Date().getTime()};${message}`;
}),
});
Next step is to create a service that will generate a random transactions. The expected format for the transaction is:
transaction_id;customer_id;card_id;atm_id;amount
To increase probability of a fraud event to happen, we can generate a pool of customer/cards and use them when generating a transactions.
// ./src/transactions-generator.ts
import { randomBytes } from 'crypto';
import { Logger } from 'winston';
export class TransactionsGenerator {
customerIds: string[] = [];
cardIds: string[] = [];
atmIds: string[] = [];
constructor(
private readonly transactionLogger: Logger,
private readonly lockedCardsLogger: Logger,
) {
// generate a pool of 10000 customers with a dedicated card for each
for (let i = 0; i < 10000; i++) {
this.customerIds.push(randomBytes(8).toString('hex'));
this.cardIds.push(randomBytes(12).toString('hex'));
}
// generate a pool of 100 atms
for (let i = 0; i < 100; i++) {
this.atmIds.push(randomBytes(2).toString('hex'));
}
}
}
Next step is to create a method to use the pools we created in order to generate a transaction and put it to a transaction.log file.
// ./src/transactions-generator.ts
generateTransaction(): void {
const transactionId = randomBytes(10).toString('hex');
const customerIndex = this.getRandomInt(this.customerIds.length);
const customerId = this.customerIds[customerIndex];
const cardId = this.cardIds[customerIndex];
const atmId = this.atmIds[this.getRandomInt(this.atmIds.length)];
const amount = this.getRandomInt(1000);
this.transactionLogger.info(
`${transactionId};${customerId};${cardId};${atmId};${amount}`,
);
}
// will generate a number from a range <0, number)
getRandomInt = (max: number) => Math.floor(Math.random() * max);
We also need a similar function to generate a locked card (using customer's pool)
// ./src/transactions-generator.ts
generateLockedCard(): void {
const customerIndex = this.getRandomInt(this.customerIds.length);
const customerId = this.customerIds[customerIndex];
const cardId = this.cardIds[customerIndex];
this.lockedCardsLogger.info(`${customerId};${cardId}`);
}
And now it's time to put all together. We will generate e.g. 100 000 transactions with a delay up to 5ms between each. Also, after every 20 000 transactions new locked card will be reported.
// ./src/transactions-generator.ts
async randomize() {
for (let i = 0; i < 100000; i++) {
this.generateTransaction();
if (i % 20000 == 0) {
this.generateLockedCard();
}
await this.delay(this.getRandomInt(5));
}
}
// ./src/index.ts
import { TransactionsGenerator } from './transactions-generator';
import { lockedCardLogger, transactionLogger } from './loggers';
const transactionsGenerator = new TransactionsGenerator(
transactionLogger,
lockedCardLogger,
);
transactionsGenerator.randomize().then(() => {
console.log('done');
while (true); // to keep the process running after the generation is done
});
Since we will be writing to kinesis streams using Kinesis Data Agent there is a couple of steps to follow to make that happen. As I do not like to install extra software on my operating system, we will use Docker to create a container for running the transactions-service with the agent configured in it.
Please follow the steps:
- Create a kinesis agent configuration file
agent.jsonintransactions-service\kinesis - Define kinesis agent and access key. We will create a dedicated kinesis IAM user with permissions for writing to the streams only in infrastructure section. For the kinesis endpoint use the endpoint from the region you provision your infrastructure in.
{
"kinesis.endpoint": "https://kinesis.eu-west-1.amazonaws.com",
"awsAccessKeyId": "<< will be configured later >>",
"awsSecretAccessKey": "<< will be configured later >>",
"flows": [
]
}
- Define a flow (flows array) for
transactionsstream (stream will be created later on). We use here the CSV to JSON converter and give proper names for the fields. Keep in mind that event timestamp is added by a logger. The data from a log file will be writter totransactionskinesis stream.
{
"filePattern": "/usr/src/app/logs/transactions*.log",
"kinesisStream": "transactions",
"dataProcessingOptions": [
{
"optionName": "CSVTOJSON",
"customFieldNames": [
"transactionTs",
"transactionId",
"customerId",
"cardNumber",
"atmId",
"amount"
],
"delimiter": ";"
}
]
},
- Define a flow for
locked-cardsstream (stream will be created later on). We need to do similar exercise as for transactions. Here we do not have the timestamp, so the field names reflect the schema generated ingenerateLockedCardfunction.
{
"filePattern": "/usr/src/app/logs/locked-cards*.log",
"kinesisStream": "locked-cards",
"dataProcessingOptions": [
{
"optionName": "CSVTOJSON",
"customFieldNames": [
"customerId",
"cardNumber"
],
"delimiter": ";"
}
]
}
- Create
start.shfile with following content
#! /bin/bash
service aws-kinesis-agent restart
npm run dev
- Now, we can generate the
Dockerfileto run the service with agent watching files and writing them to streams. We will use Amazon Linux 2023 as a base image, install and configure agent as stated in the configuration guide. As an entry point, we will restart kinesis agent and start the Node server.
FROM amazonlinux:2023
RUN dnf install -y aws-kinesis-agent which findutils initscripts nodejs
COPY ./kinesis/agent.json /etc/aws-kinesis/agent.json
WORKDIR /usr/src/app
COPY ["package.json", "package-lock.json", "tsconfig.json", "./"]
COPY ./src ./src
COPY ./start.sh start.sh
RUN chmod +x start.sh
# Installs all packages
RUN npm install
# Runs the dev npm script to build & start the server
ENTRYPOINT [ "./start.sh" ]
- And
docker-compose.ymlto run it
version: '3.8'
services:
transactions-service:
container_name: transactions-service
build:
context: ./transactions-service
dockerfile: Dockerfile
image: transactions-service:latest
networks:
- transactions-network
networks:
transactions-network:
driver: bridge
volumes:
cache:
driver: local
- To verify if all was configured and working as expected, please run
docker compose up --build. After a while you should see on the console transactions generated by the service.
Fraud detector
We will use Data Stream API with Java to build the application. Please follow the steps to create empty project. Once the project is created add 2 extra dependencies required to connect to Kinesis Data Stream. The libs are available in apache maven repository.
kdaVersion = '1.2.0'
repositories {
mavenCentral()
maven {
url "https://repository.apache.org/content/repositories/release"
mavenContent {
snapshotsOnly()
}
}
}
flinkShadowJar "org.apache.flink:flink-connector-kinesis:${flinkVersion}"
flinkShadowJar "com.amazonaws:aws-kinesisanalytics-runtime:${kdaVersion}"
We would like to have a possibility to configure our Flink application without a need of re-compilation. In that case we need to define a set of properties that can be injected to the application during job initialization. The parameters we would like to control are:
- transactions stream name
- locked cards stream name
- alerts stream name
- excessive transactions number - a number of transaction within a specified window size (another paremeter) to be considerd as a fraud
- excessive transactions window size
- scam detector small amount - an amount to be used as a starting point for a detecting a scammer
- scam detector large amount - an amount to be considered as a fraud operation done by a scammer if followed by a small one
- scam detector window - a time window size to detect a scammer
Example transactions flow for a scammer detection:

We should consider only transactions that happen within t(3) as a fraud as it is only a case when a small transaction is followed by a large one within specified time window. The next two transaction would also be considered as a fraud only if we would increase the window size.
To define all required parameters we will use application properties provided by KinesisAnalyticsRuntime.getApplicationProperties().
Let's create a class to read the parameters from the Properties:
// /src/main/java/com/cloudsoft/config/JobProperties.java
package com.cloudsoft.config;
import java.util.Properties;
public class JobProperties {
private final String transactionsStream;
private final String lockedCardsStream;
private final String alertsStream;
private final String region;
private final int excessiveTransactionWindow;
private final int excessiveTransactionCount;
private final int scamDetectorSmallAmount;
private final int scamDetectorLargeAmount;
private final int scamDetectorTime;
public JobProperties(final Properties applicationProperties) {
this.region = applicationProperties.getProperty("region", "eu-west-1");
this.transactionsStream = applicationProperties.getProperty("transactionsStreamName", "transactions");
this.lockedCardsStream = applicationProperties.getProperty("lockedCardsStreamName", "locked-cards");
this.alertsStream = applicationProperties.getProperty("alertsStreamName", "transaction-alerts");
this.excessiveTransactionWindow = getInt(applicationProperties,"excessiveTransactionWindow", "15");
this.excessiveTransactionCount = getInt(applicationProperties,"excessiveTransactionCount", "10");
this.scamDetectorSmallAmount = getInt(applicationProperties,"scamDetectorSmallAmount", "1");
this.scamDetectorLargeAmount = getInt(applicationProperties,"scamDetectorLargeAmount", "900");
this.scamDetectorTime = getInt(applicationProperties,"scamDetectorTime", "30");
}
private static int getInt(final Properties applicationProperties, String key, String defaultValue) {
return Integer.parseInt(applicationProperties.getProperty(key, defaultValue));
}
// getters here
}
we can start using the class in our job class. Create another class, called FraudDetectorJob, which will be central point of our application.
// /src/main/java/com/cloudsoft/FraudDetectorJob.java
package com.cloudsoft;
// imports here
public class FraudDetectorJob {
public JobExecutionResult execute() throws Exception {
// create an execution envirnoment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get the properties from the runtime envirnoment and store in the JobProperties object
JobProperties jobProperties = new JobProperties(
KinesisAnalyticsRuntime.getApplicationProperties().get("FraudDetectorConfiguration"));
// execute the job
return env.execute("Fraud detector");
}
}
Since all the properties are defined, we can start creating input streams for our application. We will be reading data with transactions and locked cards information. Names of the stream are provided in properties and available in JobProperties object. The consumer we need to create to read from Kinesis Data Stream is FlinkKinesisConsumer.
// /src/main/java/com/cloudsoft/StreamSinkFactory.java
package com.cloudsoft;
// imports here
public final class StreamSinkFactory {
private StreamSinkFactory() {
}
public static DataStream<Transaction> createTransactionsSource(
final StreamExecutionEnvironment env,
final JobProperties jobProperties) {
return createSource(env, jobProperties.getTransactionsStream(), "transactions", jobProperties.getRegion(),
new TransactionDeserializer());
}
public static DataStream<LockedCard> createLockedCardsSource(
final StreamExecutionEnvironment env,
final JobProperties jobProperties) {
return createSource(env, jobProperties.getLockedCardsStream(), "locked-cards", jobProperties.getRegion(),
new LockedCardDeserializer());
}
private static <T> DataStream<T> createSource(
final StreamExecutionEnvironment env,
final String streamName,
final String name,
final String region,
final DeserializationSchema<T> deserializationSchema) {
Properties inputProperties = new Properties();
inputProperties.setProperty(AWS_REGION, region);
return env.addSource(new FlinkKinesisConsumer<>(streamName, deserializationSchema, inputProperties)).name(name);
}
}
And we need to define models and corresponding JSON deserializers. Let's start with LockedCard model:
// /src/main/java/com/cloudsoft/model/LockedCard.java
package com.cloudsoft.model;
public class LockedCard {
private String cardNumber;
private String customerId;
public LockedCard() {
}
// getters & setters
}
LockedCardDeserializer:
// /src/main/java/com/cloudsoft/model/LockedCardDeserializer.java
package com.cloudsoft.model;
public class LockedCardDeserializer implements DeserializationSchema<LockedCard> {
private final ObjectMapper mapper = new ObjectMapper();
@Override
public LockedCard deserialize(byte[] message) throws IOException {
return mapper.readValue(message, LockedCard.class);
}
@Override
public boolean isEndOfStream(LockedCard nextElement) {
return false;
}
@Override
public TypeInformation<LockedCard> getProducedType() {
return TypeInformation.of(LockedCard.class);
}
}
Transaction model:
// /src/main/java/com/cloudsoft/model/Transaction.java
package com.cloudsoft.model;
public class Transaction {
private long transactionTs;
private String transactionId;
private String cardNumber;
private String customerId;
private String atmId;
private int amount; // for the simplicity
// getters & setters
}
and TransactionDeserializer:
// /src/main/java/com/cloudsoft/model/TransactionDeserializer.java
package com.cloudsoft.model;
public class TransactionDeserializer implements DeserializationSchema<Transaction> {
private final ObjectMapper mapper = new ObjectMapper();
@Override
public Transaction deserialize(byte[] message) throws IOException {
return mapper.readValue(message, Transaction.class);
}
@Override
public boolean isEndOfStream(Transaction nextElement) {
return false;
}
@Override
public TypeInformation<Transaction> getProducedType() {
return TypeInformation.of(Transaction.class);
}
}
Before we use the streams in FraudDetectorJob there is one more aspect to be highlighted. We want to use transaction's event time as a time notion for our data stream. This require defining watermarks strategy to be generated with the data stream. Since we know our stream has events generated in ascending order, we can use the simplest built in watermark strategy.
// /src/main/java/com/cloudsoft/FraudDetectorJob.java
JobProperties jobProperties = new JobProperties(
KinesisAnalyticsRuntime.getApplicationProperties().get("FraudDetectorConfiguration"));
// define watermark strategy and extract timestamp for every event
WatermarkStrategy<Transaction> watermarkStrategy = WatermarkStrategy.<Transaction>forMonotonousTimestamps()
.withTimestampAssigner((e, t) -> e.getTransactionTs());
// generate locked card stream
DataStream<LockedCard> lockedCardsStream = createLockedCardsSource(env, jobProperties);
// generate transactions stream with assigned watermark strategy
DataStream<Transaction> transactionsStream = createTransactionsSource(env, jobProperties)
.assignTimestampsAndWatermarks(watermarkStrategy).name("transactions-with-watermark");
Now, with all the side objects defined we can start focusing on the main requirements. We will start with the first one, which is detecting transactions done by locked cards. To achieve that we will use boradcast state pattern.
The boradcast state pattern requires defining a StateDescriptor type of object to keep the state on task's machines. We would like to store locked card information and have the data indexed by a card number so the lookup would be fast. In that case we will use a subclass of StateDescriptor with type MapStateDescriptor.
// /src/main/java/com/cloudsoft/tasks/LockedCardsProcessFunction.java
package com.cloudsoft.tasks;
public class LockedCardsProcessFunction {
// key would be a card number and object would be the card itself
public static final MapStateDescriptor<String, LockedCard> lockedCardMapStateDescriptor =
new MapStateDescriptor<>("locked_cards", BasicTypeInfo.STRING_TYPE_INFO, Types.POJO(LockedCard.class));
}
Next step is to use the descriptor to create a BroadcastStream out of DataStream and connect it with the transactions stream. Connected stream can be processed by a function that will check incomming transactions against locked cards. As a result, it will produce new stream with Alert objects.
// /src/main/java/com/cloudsoft/FraudDetectorJob.java
DataStream<Transaction> transactionsStream = createTransactionsSource(env, jobProperties)
.assignTimestampsAndWatermarks(watermarkStrategy).name("transactions-with-watermark");
// create a BroadcastStream
BroadcastStream<LockedCard> lockedCardBroadcastStream = lockedCardsStream.broadcast(lockedCardMapStateDescriptor);
DataStream<Alert> lockedCardsAlert = transactionsStream
.keyBy(Transaction::getCustomerId) // key the transactions stream by customer id
.connect(lockedCardBroadcastStream) // connect with the broadcast stream
.process(new LockedCardsProcessFunction()) // and process the data resulting in new stream with alerts
.name("locked-cards-process-function");
Wecan get back to LockedCardsProcessFunction to add missing parts required to detect frauds.
// /src/main/java/com/cloudsoft/tasks/LockedCardsProcessFunction.java
public class LockedCardsProcessFunction extends KeyedBroadcastProcessFunction<String, Transaction, LockedCard, Alert> {
public static final MapStateDescriptor<String, LockedCard> lockedCardMapStateDescriptor =
new MapStateDescriptor<>("locked_cards", BasicTypeInfo.STRING_TYPE_INFO, Types.POJO(LockedCard.class));
@Override
public void processElement(
Transaction transaction,
KeyedBroadcastProcessFunction<String, Transaction, LockedCard, Alert>.ReadOnlyContext ctx,
Collector<Alert> out
) throws Exception {
if (ctx.getBroadcastState(lockedCardMapStateDescriptor).contains(transaction.getCardNumber())) {
out.collect(new Alert("LOCKED_CARD", "Suspicious transaction " + transaction));
}
}
@Override
public void processBroadcastElement(
LockedCard card,
KeyedBroadcastProcessFunction<String, Transaction, LockedCard, Alert>.Context ctx,
Collector<Alert> out
) throws Exception {
ctx.getBroadcastState(lockedCardMapStateDescriptor).put(card.getCardNumber(), card);
}
}
LockedCardsProcessFunction extends generic KeyedBroadcastProcessFunction, where the types are following:
- String - key type of incomming keyed stream (non-broadcasted)
- Transaction - input type of the incomming stream (non-broadcasted)
- LockedCard - input type of broadcated stream
- Alert - output type
There are 2 methods we are overriding:
- processBroadcastElement - called for every new element in the broadcast stream. When it being called, we load the state from the context and put the broadcasted element to it
- processElement - called for every element in the incomming stream. We need to check if a card number from the element is not present in the state containing locked cards information. If so, we report an alert.
And that is all regarding the first requirement. We can move on to the second one, which is 'excessive number of transaction'. Please consider ten transactions done within a minute for the same customer/card. That should caught one's attention. And this is the second alert we will be implementing.
// /src/main/java/com/cloudsoft/FraudDetectorJob.java
DataStream<Alert> excessiveTransactions = transactionsStream // take the transaction stream
.map(new MapFunction<Transaction, Tuple2<Transaction, Integer>>() {
// create a touple for every transaction. A second element in a touple
// is a counter. We init it with 1
@Override
public Tuple2<Transaction, Integer> map(Transaction value) {
return new Tuple2<>(value, 1);
}
})
.name("transaction-tuple-mapper")
.keyBy(t -> t.f0.getCustomerId()) // we key the stream by a customer id
// and creating an event tumbling window with defined size
.window(TumblingEventTimeWindows.of(Time.seconds(jobProperties.getExcessiveTransactionWindow())))
.sum(1) // sum key-ed stream using secong element of a tuple
.name("transaction-counter")
.flatMap(new ExcessiveTransactionsFilter(jobProperties.getExcessiveTransactionCount())) // and call a filter function
.name("excessive-transactions-filter");
and the simple filter function:
// /src/main/java/com/cloudsoft/tasks/ExcessiveTransactionsFilter.java
package com.cloudsoft.tasks;
// imports here
public class ExcessiveTransactionsFilter implements FlatMapFunction<Tuple2<Transaction, Integer>, Alert> {
private final int threshold;
// we pass on the threshold from properties
public ExcessiveTransactionsFilter(final int threshold) {
this.threshold = threshold;
}
@Override
public void flatMap(Tuple2<Transaction, Integer> value, Collector<Alert> out) {
// if the sum if equal or greathen the threshold -> generate alert
if (value.f1 >= threshold) {
out.collect(new Alert("EXCESSIVE_TRANSACTIONS",
"Excessive transactions for customer=" + value.f0.getCustomerId()));
}
}
}
And that is all regarding the second requirement. Now, it's time to move on to scammer detection.
The requirement for scam detector were described a few lines above, but to quickly sumarize it we need to find a small amount transaction (task parameter) that was followed by a large one withing defined time window (e.g. 1$ followed by 950$ withing 30 second window).
This time we will put the whole logic within KeyedProcessFunction that will be called for every element of keyed stream.
// /src/main/java/com/cloudsoft/FraudDetectorJob.java
DataStream<Alert> scammedTransactions = transactionsStream
.keyBy(Transaction::getCustomerId) // key stream by customer id
// and process every element by ScamDetector function
.process(new ScamDetector(jobProperties.getScamDetectorSmallAmount(),
jobProperties.getScamDetectorLargeAmount(), jobProperties.getScamDetectorTime()))
.name("scam-detector");
And the ScamDetector process function:
// /src/main/java/com/cloudsoft/tasks/ScamDetector.java
package com.cloudsoft.tasks;
// imports here
import java.io.IOException;
public class ScamDetector extends KeyedProcessFunction<String, Transaction, Alert> {
// state to remember if previous transaction was small one
private transient ValueState<Boolean> smallTransactionFlagState;
// state to keep timer so we can monitor 'window'
private transient ValueState<Long> timerState;
private final int smallAmount;
private final int largeAmount;
private final long time;
public ScamDetector(int smallAmount, int largeAmount, long time) {
this.smallAmount = smallAmount;
this.largeAmount = largeAmount;
this.time = time;
}
/**
* Inits the state - it's called before actual processing. The state will be store in execution context
*/
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"small_transaction", Types.BOOLEAN);
smallTransactionFlagState = getRuntimeContext().getState(flagDescriptor);
ValueStateDescriptor<Long> timerDescriptor = new ValueStateDescriptor<>(
"timer-state",
Types.LONG);
timerState = getRuntimeContext().getState(timerDescriptor);
}
// called for ever element in the stream
@Override
public void processElement(
Transaction transaction,
KeyedProcessFunction<String, Transaction, Alert>.Context context,
Collector<Alert> collector
) throws Exception {
Boolean previousTransactionWasSmall = smallTransactionFlagState.value();
// Check the previous transaction's state. If non null, it was a small one
if (previousTransactionWasSmall != null) {
if (transaction.getAmount() > largeAmount) { // if the current is large -> generate alert
collector.collect(new Alert("SCAM", "Suspicious operations for customer " + transaction.getCustomerId()));
}
cleanUp(context); // and clean up current state
}
// the current transaction is small, so remember the state and register/reset timer to monitor the window
if (transaction.getAmount() <= smallAmount) {
// Set the flag to true
smallTransactionFlagState.update(true);
// set the timer and timer state
long timer = context.timerService().currentProcessingTime() + (time * 1000);
context.timerService().registerProcessingTimeTimer(timer);
timerState.update(timer);
}
}
// called when the timer is triggered
// we need to reset the state as we missed a window for scammer
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Alert> out) {
timerState.clear();
smallTransactionFlagState.clear();
}
// reset the current state
private void cleanUp(Context context) throws IOException {
Long timer = timerState.value();
context.timerService().deleteProcessingTimeTimer(timer);
timerState.clear();
smallTransactionFlagState.clear();
}
}
This was the most complicated use case, but I think if you read it carefully all the logic will be clear. We are done with all three requirements now, but there is still something left to do.
We have 3 separate data streams with alerts generated by fraud detection tasks, but streams have no neither consumer nor sink. So, the next step would be to define a sink. If we return to the diagram, we would like the alert to be written to a dedicated kinesis data stream (alerts) and from there any client could read and act if needed.
The Alert is a POJO object and we would like to stream it as a JSON, so relevant serializer would be needed.
// /src/main/java/com/cloudsoft/model/Alert.java
package com.cloudsoft.model;
import java.util.Objects;
public class Alert {
private String type;
private String msg;
public Alert() {
}
public Alert(String type, String msg) {
this.type = type;
this.msg = msg;
}
// getters & setters
}
And serializer
// /src/main/java/com/cloudsoft/model/AlertSerializer.java
package com.cloudsoft.model;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.api.common.serialization.SerializationSchema;
public class AlertSerializer implements SerializationSchema<Alert> {
private final ObjectMapper mapper = new ObjectMapper();
@Override
public byte[] serialize(Alert element) {
try {
return mapper.writeValueAsBytes(element);
} catch (JsonProcessingException e) {
throw new RuntimeException("Unable to serialize object " + element.toString(), e);
}
}
}
Now we can get back to StreamSinkFactory and define a sink for the alert stream:
// /src/main/java/com/cloudsoft/StreamSinkFactory.java
public static KinesisStreamsSink<Alert> createAlertSink(final JobProperties jobProperties) {
Properties outputProperties = new Properties();
outputProperties.setProperty(AWS_REGION, jobProperties.getRegion());
return KinesisStreamsSink.<Alert>builder()
.setKinesisClientProperties(outputProperties)
.setSerializationSchema(new AlertSerializer()) // use serializer we created
.setStreamName(jobProperties.getAlertsStream()) // use stream name from properties
.setPartitionKeyGenerator(element -> String.valueOf(element.hashCode())) // generate partition key
.build();
}
and now it's time to use it. Flink gives you an option to union streams and we will use that to combine all our alerts into sigle stream:
// /src/main/java/com/cloudsoft/FraudDetectorJob.java
lockedCardsAlert.union(excessiveTransactions, scammedTransactions).sinkTo(createAlertSink(jobProperties));
Last, but not least is to define a main method for our application.
// /src/main/java/com/cloudsoft/FraudDetector.java
package com.cloudsoft;
public class FraudDetector {
public static void main(String[] args) throws Exception {
new FraudDetectorJob().execute();
}
}
and register it in build.gradle so that it can be defined in MANIFEST.MF
// artifact properties
group = 'com.cloudsoft'
version = '0.1'
mainClassName = 'com.cloudsoft.FraudDetector'
description = "Froud detecttor"
You can now build your Flink program by running ./gradlew clean shadowJar. It will build fat jar ready to be deployed as Kinesis Data Analytics application.
Infrastructure
- IAM User to Kinesis Data Agent
We need to create access key and access secret for Kinesis Data Agent. For that purpose we will create IAM user with permissions required to write to Kinesis Data Stream. There is also required Cloudwatch policy. In my case following was configured:
Get the access key and secret and paste them in relevant place in transactions-service/kinesis/agent.json
- Kinesis Data Analytics infrastructure
In this step we will provision whole infrastructure and deploy the application built in previous step. The infrastructure will be provisioned using Terraform. In that case we need to start with basic terraform configuration.
// main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
backend "s3" {
bucket = "<<put bucket name to store terraform state>>"
key = "kinesis-data-analytics/terraform.tfstate"
region = "eu-west-1"
encrypt = "true"
}
}
provider "aws" {
region = "eu-west-1"
default_tags {
tags = {
project = "kinesis-data-analytics"
managed-by = "Terraform"
}
}
}
Please note the bucket for storing state needs to be created beforehand.
Now, we can proceed with the application itself. We need to define a bucket and upload the application so that it's available for Apache Flink.
// kinesis.tf
resource "aws_s3_bucket" "kda_scripts_bucket" {
bucket = "<< your bucket name >>"
}
resource "aws_s3_object" "kda_fraud_detector_app" {
key = "apps/flink/fraud-detector-0.1.jar"
bucket = aws_s3_bucket.kda_scripts_bucket.id
source = "../froud-detector/build/libs/froud-detector-0.1-all.jar"
etag = filemd5("../froud-detector/build/libs/froud-detector-0.1-all.jar")
}
Please put the bucket name of your choice as well as valid path to application jar you've configured.
Our application needs data streams to read data from and write alerts to. We will provision them with basic setup and provisioned capacity mode with shard count 1.
// kinesis.tf
resource "aws_kinesis_stream" "transactions" {
name = "transactions"
shard_count = 1
retention_period = 24
stream_mode_details {
stream_mode = "PROVISIONED"
}
}
resource "aws_kinesis_stream" "locked_cards" {
name = "locked-cards"
shard_count = 1
retention_period = 24
stream_mode_details {
stream_mode = "PROVISIONED"
}
}
resource "aws_kinesis_stream" "alerts" {
name = "alerts"
shard_count = 1
retention_period = 24
stream_mode_details {
stream_mode = "PROVISIONED"
}
}
All 3 streams have the same settings, but it so small resource that I did not decide to create a separate module for it.
In the next step we will define a role required for aws_kinesisanalyticsv2_application resource. For that purpose, we will use existing policies (AmazonKinesisAnalyticsFullAccess and AmazonKinesisFullAccess) as well as extend it with required access to read application from S3.
// kinesis.tf
data "aws_iam_policy_document" "kda_scripts_bucket_policy" {
statement {
sid = "AllowReadScript"
actions = ["s3:Get*", "s3:List*"]
resources = ["${aws_s3_bucket.kda_scripts_bucket.arn}", "${aws_s3_bucket.kda_scripts_bucket.arn}/*"]
}
statement {
sid = "AllowListShards"
actions = ["kinesis:ListShards"]
resources = ["*"]
}
}
data "aws_iam_policy_document" "kinesis_assume_role_policy" {
statement {
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["kinesisanalytics.amazonaws.com"]
}
}
}
resource "aws_iam_role" "fraud_detector_job_role" {
name = "fraud-detector-job-role"
assume_role_policy = data.aws_iam_policy_document.kinesis_assume_role_policy.json
}
resource "aws_iam_role_policy_attachment" "fraud_detector_kinesis_service_attachment" {
policy_arn = "arn:aws:iam::aws:policy/AmazonKinesisAnalyticsFullAccess"
role = aws_iam_role.fraud_detector_job_role.name
}
resource "aws_iam_role_policy_attachment" "fraud_detector_kinesis_full_access_attachment" {
policy_arn = "arn:aws:iam::aws:policy/AmazonKinesisFullAccess"
role = aws_iam_role.fraud_detector_job_role.name
}
resource "aws_iam_role_policy" "fraud_detector_job_role_allow_s3_read" {
name = "allow-s3-bucket-policy"
role = aws_iam_role.fraud_detector_job_role.name
policy = data.aws_iam_policy_document.kda_scripts_bucket_policy.json
}
We have almost everything prepared. The last part is to define a flink application and setup both parameters for the application and the execution environment. As mentioned before, we will use aws_kinesisanalyticsv2_application resource.
// kinesis.tf
resource "aws_kinesisanalyticsv2_application" "fraud_detector" {
name = "fraud-detector-application"
runtime_environment = "FLINK-1_15"
service_execution_role = aws_iam_role.fraud_detector_job_role.arn
application_configuration {
application_code_configuration { // application source code
code_content {
s3_content_location {
bucket_arn = aws_s3_bucket.kda_scripts_bucket.arn
file_key = aws_s3_object.kda_fraud_detector_app.key
}
}
code_content_type = "ZIPFILE"
}
environment_properties { // application configuration
property_group {
property_group_id = "FraudDetectorConfiguration" // group and params name need to match
property_map = { // properties defined in JobProperties
transactionsStreamName = aws_kinesis_stream.transactions.name
lockedCardsStreamName = aws_kinesis_stream.locked_cards.name
alertsStreamName = aws_kinesis_stream.alerts.name
region = "eu-west-1"
excessiveTransactionWindow = "30"
excessiveTransactionCount = "10"
scamDetectorSmallAmount = "1"
scamDetectorLargeAmount = "950"
scamDetectorTime = "30"
}
}
}
flink_application_configuration { // runtime configuration, for more details please refer to documentation
checkpoint_configuration {
configuration_type = "DEFAULT"
}
monitoring_configuration {
configuration_type = "CUSTOM"
log_level = "INFO"
metrics_level = "TASK"
}
parallelism_configuration { // basic setup with minimum resources, needs to be tuned for production deployment
auto_scaling_enabled = false
configuration_type = "CUSTOM"
parallelism = 1
parallelism_per_kpu = 1
}
}
}
}
And that is all for the infrastructure configuration. We can deploy it now and move to the next chapter, which is end to end testing our solution.
Testing
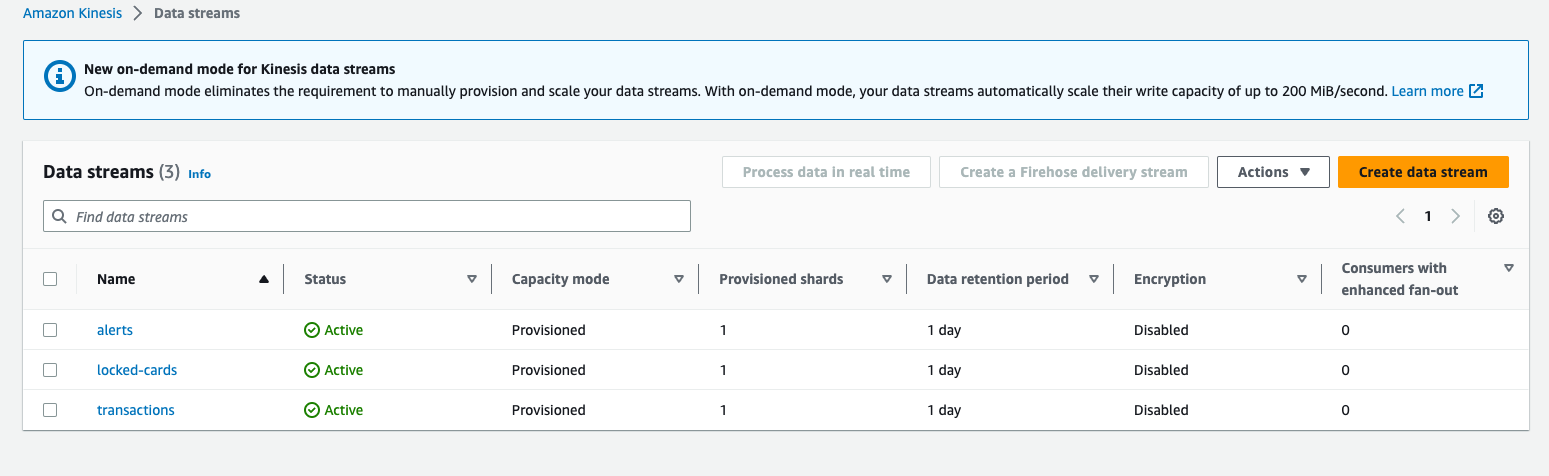
After provisioning the infrastructure, you can go to AWS Console -> Kinesis -> Data Stream. There should be 3 streams created:
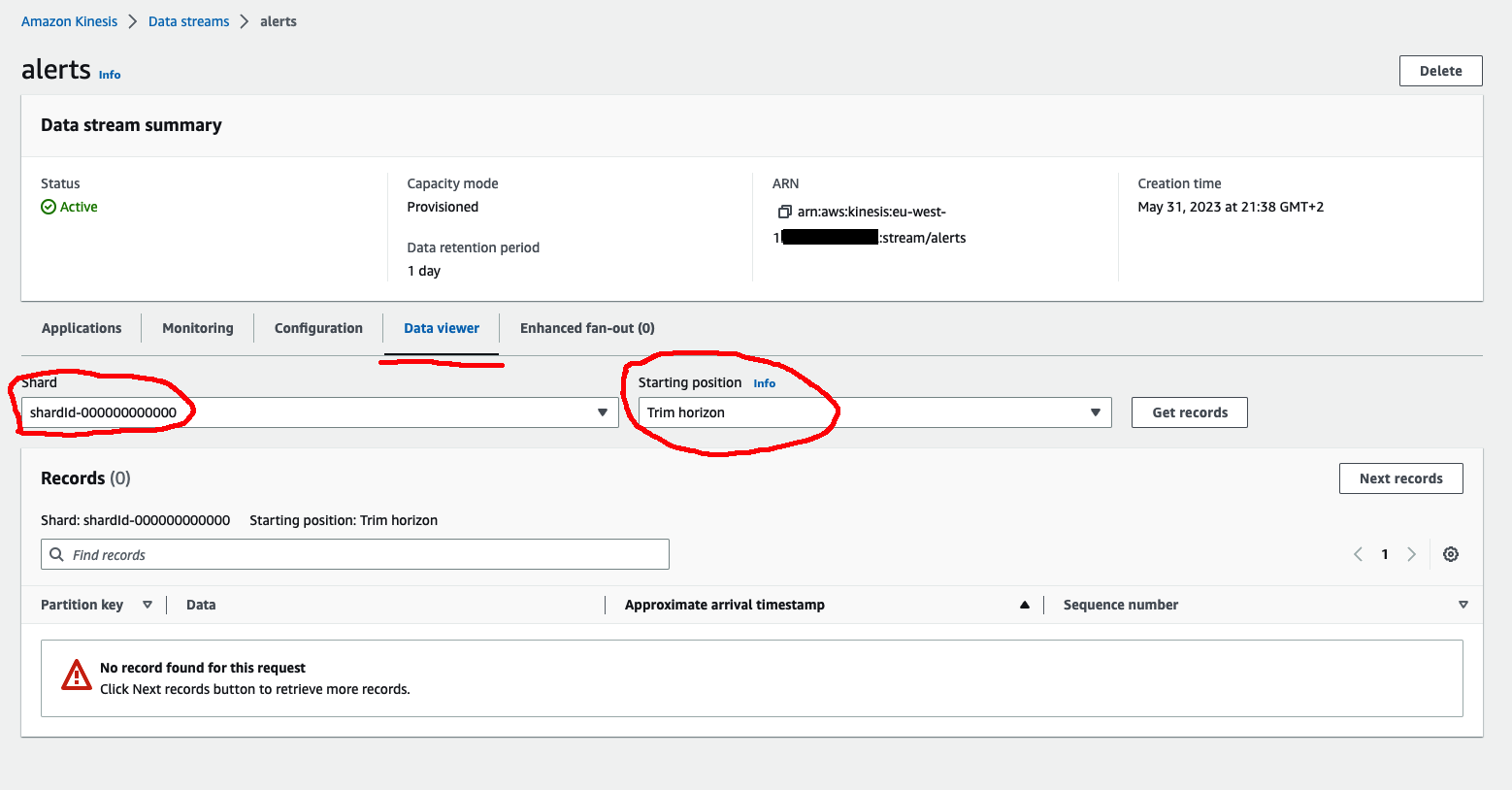
Streams are empty for now (can be verified using Data Viewer with selecting a shard and Starting position)
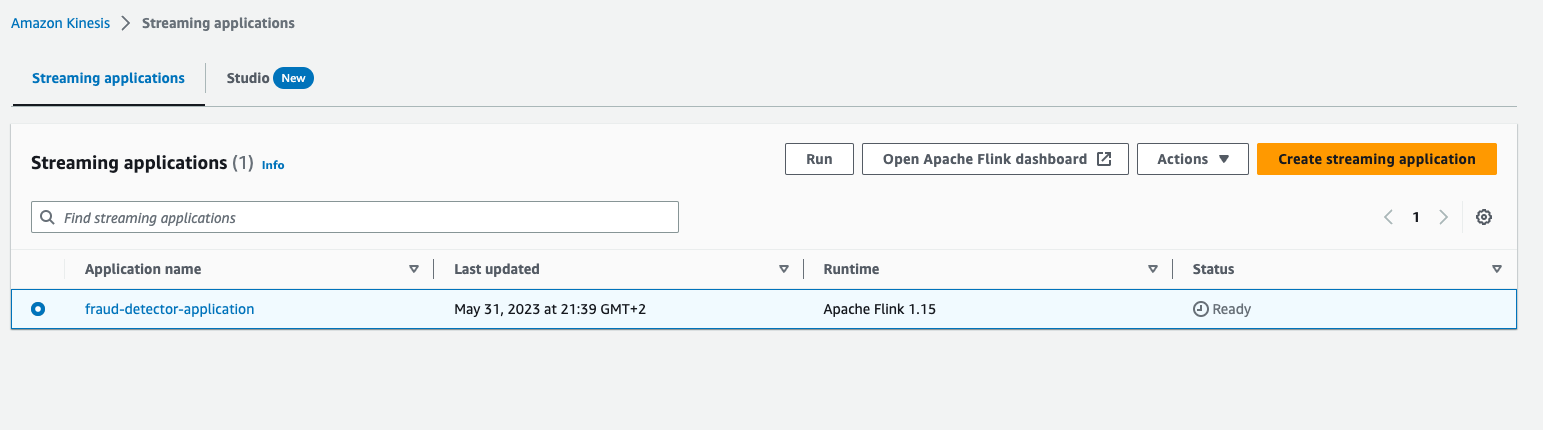
And also our application should be deployed and in Ready state. Ready state means it was deployed succesfully, but it cannot handle data streams. To start processing data we need to start it by clicking 'Run' button. After clicking the 'Run' button it will ask about 'Checkpoint' - this is to support failover recovery and handle missing data if we processed any data from the stream. It will take a while to make it operational.
Once is ready, we can open 'Flink Dashboard' to see data streams visualisation.
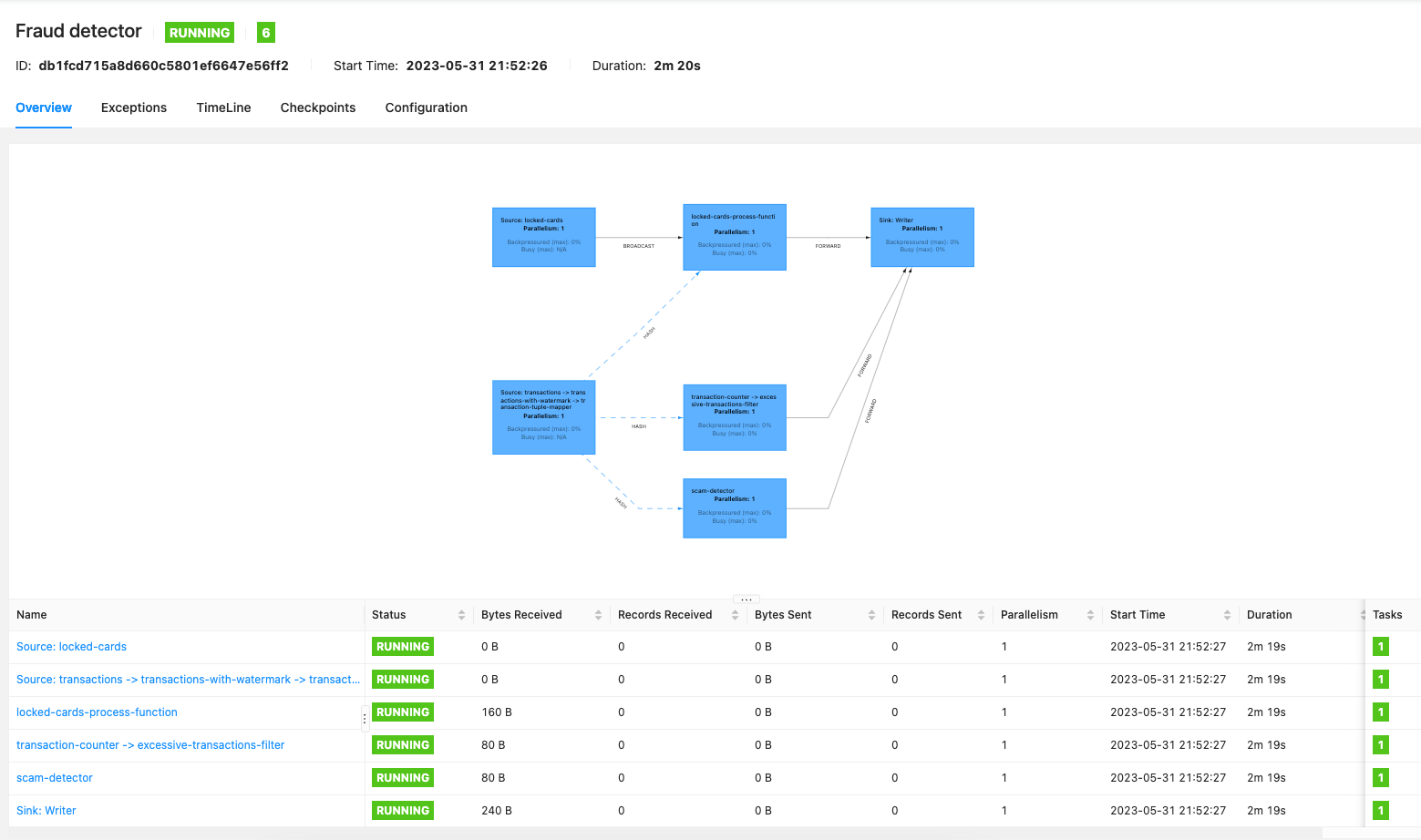
Currently no data is comming to stream so received bytes shows 0. After starting the simulator, numbers should increase and some alerts should be generated. Depends on your random data, different types of alert could have been generated. But there should be some (visible as number in sink operator)
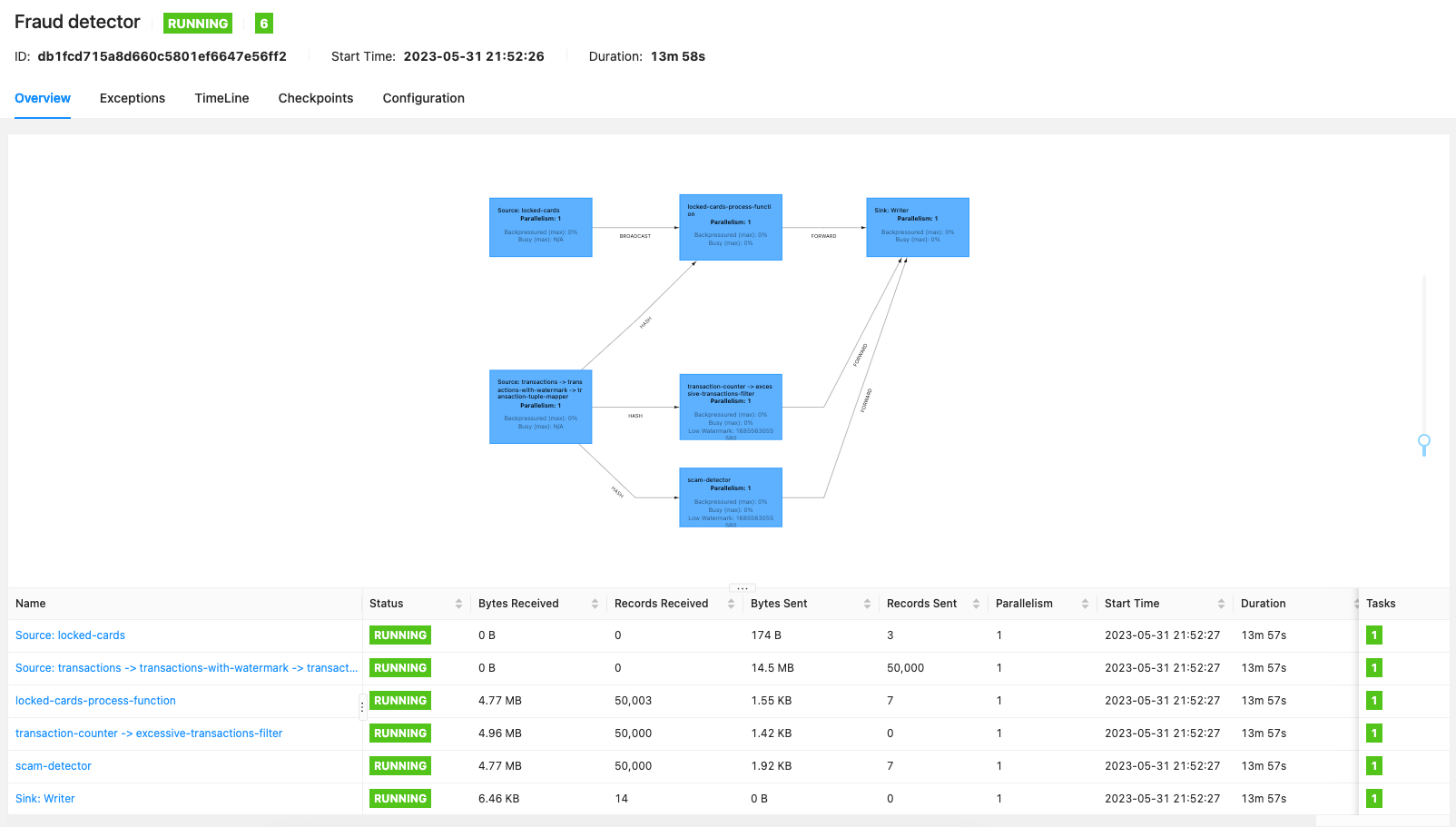
We can verify some random values if are valid, for instance for SCAM detection:
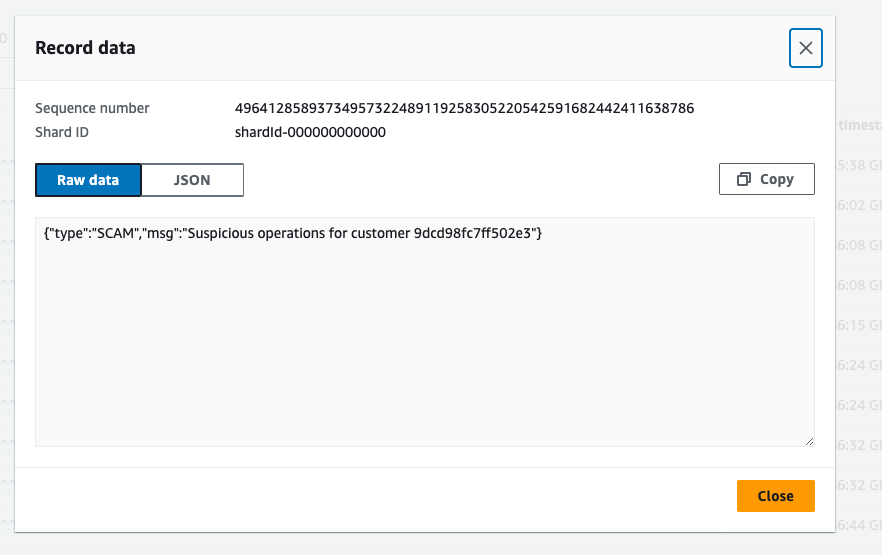
and
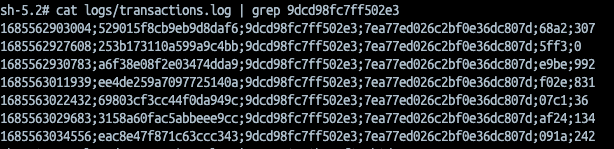
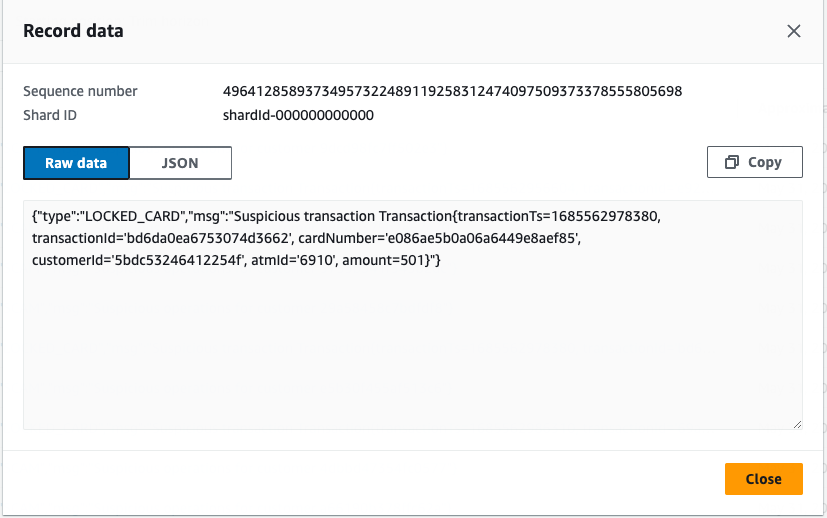
There is a small transaction (0) followed by a large one (992). The same verification we can do for LOCKED CARDS.
and
Summary
That is all regarding Kinesis Data Analytics. I hope you understand the basic concept of real time data analysis and find the Apache Flink powerful framework for such tasks.
Please remember to delete all the resources you created to avoid additional costs as the services we were using are not available under free tier.
All the code is available on github.